Пишем RSS агрегатор на Delphi
Рубрика: Delphi -> Программирование -> Журнал Хакер -> Статьи
Метки: delphi | rss | программирование
Просмотров: 10335

У каждого из нас есть множество любимых сайтов, за обновлениями которых постоянно приходится следить. Хорошо, когда таких сайтов немного: зашел на главную страницу, почитал новости и ушел. Беда в том, что у бывалых пользователей интернета таких сайтов несколько десятков. Как уследить за каждым из них? Постоянно бегать по десяткам ссылок, гоняя драгоценный трафик? Нет! Гораздо проще и удобнее получать новости в формате RSS.

Как известно, для чтения новостей в формате RSS созданы программы – RSS-агрегаторы. Стоим им только подсунуть ссылку на ленту новостей, как они тут же начинают бдительно следить за обновлениями и показывать все топики в удобном виде. Многие разработчики уже давно встраивают читалки RSS в свои браузеры. По такому пути пошли разработчики Opera, FireFox, IE и многие другие.
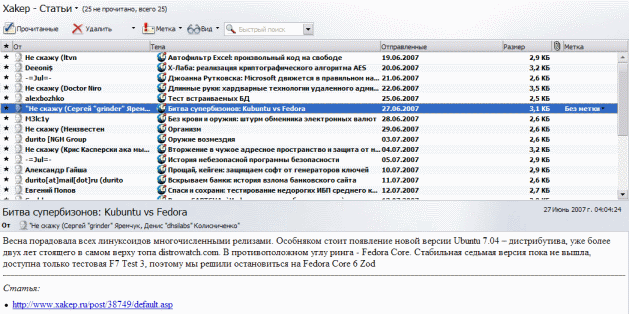
Использовать готовые программки - хорошо, но еще лучше научиться создавать их самостоятельно (это подарит тебе удивительную легкость в плане получения и хакерского распределения информации ;)). Для этого нужно только выделить время и разобраться с форматом RSS.
Теория RSS
Аббревиатура RSS расшифровывается как Really Simple Syndication, что в переводе на великий и могучий означает «действительно простая доставка». Благодаря этому формату все мы можем оперативно получать новости со своих любимых порталов, не дожидаясь долгой загрузки сайтов. Мы получаем только самое необходимое, например тему новости, коротенькое описание, дату публикации и ссылку на полный текст. Экономия трафика, особенно для GPRS-юзеров, очень существенная.
Но не стоит думать, что формат RSS предназначен лишь для публикации новостей. Вовсе нет. Используя эту технологию, можно запросто передавать информацию, скажем, с форума, гостевой книги и т.д.
Немного истории
Впервые в истории мысли о подобной технологии распределения информации возникли у мозговитых парней из компании User Land, которые в 1997 году зарелизили свой формат - sсripting news. Формат получился неплохим, но не прижился. Причем не прижился по вине всем известной компании Netscape. В то время она выступала законодателем моды в мире интернет-технологий, и конкурировать с ней было довольно тяжело. Пару лет спустя выходит разработанный на основе sсripting news формат RSS 0.9. Как ни странно, его разработчиком стала сама Netscape. Формат начал постепенно вливаться в массы, но многие сочли его слишком сложным и неудобным, поэтому Netscape ничего не оставалось, как заняться его совершенствованием. В результате была выпущена версия 0.9.1. На этот раз формат получился достаточно гибким и в то же время более простым в использовании. К сожалению, и новый релиз не смог завоевать сердца web-разработчиков. В итоге Netscape решает свернуть разработку RSS и сосредоточить свои усилия на других проектах. Разумеется, наработки по проекту не были выброшены на свалку - право на разработку и развитие этого проекта было передано уже упоминавшейся компании User Land. Все те же мозговитые парни стали активно совершенствовать формат и спустя некоторое время явили миру версию 0.9.2.
В то же самое время организация RSS-Dev Working Group, борющаяся за сохранение формата версии 0.9, выпустила версию 1.0, в основу которой легли идеи версии 0.9. Версия 1.0 начала набирать обороты… и опять-таки не получила широкого признания в компьютерном сообществе по причинам, затормозившим распространение версии 0.9.
2002 год становится золотым годом для RSS. Компания User Land выпускает вторую версию (2.0) этой замечательной технологии, и уже она порождает самый настоящий бум в сфере интернет-технологий. Многие web-разработчики оценили ее привлекательность и начали использовать в своих проектах. Через год в рамках лицензии Creative Commons становится доступной спецификация к формату RSS 2.0.
Формат RSS изнутри
С точки зрения программиста лента RSS представляет собой обычный xml-подобный файл. В нем содержатся определенные спецификацией элементы. Обо всех них ты сможешь прочитать в документации, мы рассмотрим только основные:
Для того чтобы лучше разобраться с форматом, посмотри вот сюда:
Пример файла с новостями
<?xml version="1.0" encoding="windows-1251"?>
<rss version="2.0">
<channel>
<title>Мой суперсайт</title>
<link>http://mysite.com</link>
<description>Все, что вам нужно, есть здесь ?</description>
</channel>
<item>
<title>Новость 1</title>
<link>http://mysite.com/news1.txt</link>
<description>Сегодня открылся мой сайт</description>
<pubDate>Fri, 15 aug 2007 +1100</pubDate>
<author>Spider_NET</author>
</item>
</rss>
Форма программы
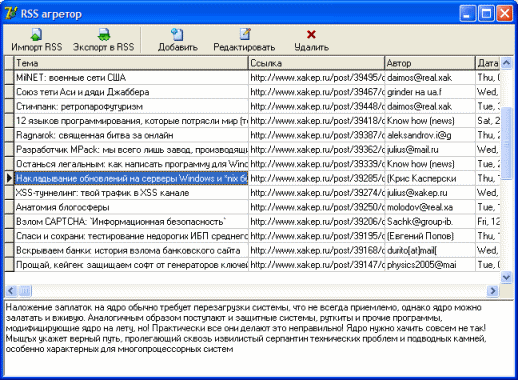
Программировать свой RSS-агрегатор мы будем на великом и могучем Delphi (редактор согласился опубликовать статью, только если я использую не менее 10 хвалебных эпитетов в адрес Delphi на 10 килобайт плайн-текста :(), поэтому запускай эту IDE и рисуй форму, подобную изображенной на рисунке.
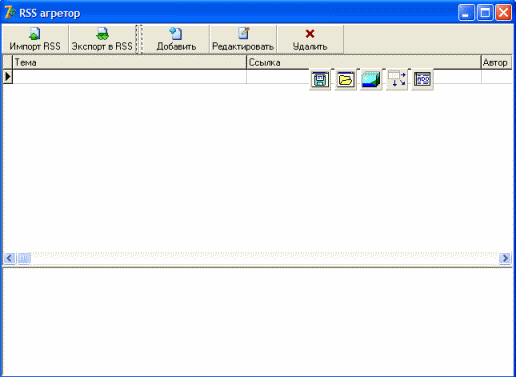
В верхней части формы у меня расположена панель с управляющими кнопками, чуть ниже - DbGrid (необходим для отображения данных из БД) и в самом низу - DBMemo (в нем будет отображаться текст новости). Я упомянул о базе данных. Сегодняшний пример действительно будет работать с базой данных. Гораздо лучше хранить и править все новости в БД, чем мучиться с текстовыми файлами. Тем более что, используя БД, ты всегда можешь с легкостью организовать поиск нужной новости и много чего еще. В качестве базы данных мы будем использовать MS Access.
Создаем БД
С выбором БД мы определились, теперь самое время ее создать и подключить к Delphi. Запускай MS Access, создавай новую БД, сохраняй ее куда-нибудь и переходи к созданию таблице в режиме конструктора.

В таблице нам потребуется 6 полей:
Сохраняем таблицу. В качестве имени я указал rss. На этом этапе можно закрыть Acсess и возвратиться к Delphi. Кидай на форму AdoTable (ADO) и DataSource (Data Access). Выбирай сначала компонент DataSource и в свойстве DataSet - AdoTable. Теперь пришла очередь центрового компонента при работе с БД – AdoTable. Дважды кликай по свойству ConnectionString. Перед тобой появится окошко, в котором тебе нужно нажать пимпу Build. На экране отобразится форма, в ней необходимо настроить подключение к БД.
Сначала перейди на закладку «Поставщик данных» и среди провайдеров найди Microsoft Jet 4.0 OLE DB Provider. Выделяй и жми «Далее». В поле выбора БД введи имя или путь к созданной БД. Если ты сохранил базу в папку с программой, то в этом поле просто укажи ее имя. Так твоя база не будет привязана к какому-то определенному пути, а всегда будет искаться в папке с программой. Установи флажок «Пустой пароль». Это необходимо для того, чтобы постоянно не выскакивало окошко с просьбой его ввода.
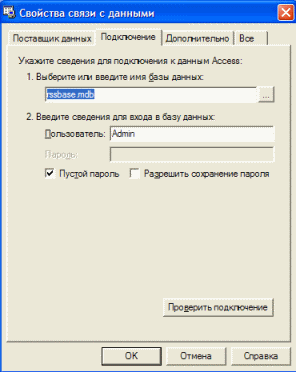
Итак, все готово, можно протестировать подключение. Нажми на кнопку «Проверить подключение». Если не было допущено ошибок, то ты увидишь сообщение с текстом: «Проверка подключения выполнена». В противном случае тебе придется перечитать часть статьи заново. Возвращайся к форме и быстренько выделяй компоненты DbGrid и DbMemo. В объектом инспекторе ищи свойство DataSource и выбирай в нем DataSource1. Теперь эти компоненты связаны с нашей таблицей, а значит, в них будут отображаться данные из БД.
Теперь все готово для того, чтобы установить активность нашей таблице. Опять же выбирай AdoTable, в свойстве TableName находи нашу таблицу, свойство Active выставляй в true. В DbGrid должны появиться колонки с именами созданных нами полей. Отображать все поля в DbGrid нам абсолютно ни к чему, поэтому 2 раза кликай по компоненту AdoTable и в появившемся окне нажимай
В своем примере я дал всем полям нормальные имена, поменял размерность и сделал невидимыми поля Description и ID. Значение поля Description у нас будет отображаться в DbMemo, а значение ID видеть вообще не нужно.
Импортируем RSS
Для импорта новостей нам придется открыть файл с новостями и пропарсить его, вытаскивая информацию о них. Названия наиболее важных элементов формата RSS я описал, поэтому можешь написать парсер самостоятельно. Но минусы подобного пути - муторность отладки и проблемы с совместимостью. Другой способ решения этой задачи предусматривает использование готового xml-парсера. Их достаточно много, поэтому есть из чего выбрать. Для нашего примера мы так и сделаем - воспользуемся разработкой от Microsoft – MSXML. Модуль для работы с этим парсером уже есть в составе Delphi, поэтому тебе не придется ничего дополнительно качать и устанавливать. Работа с парсером происходит через объект XMLDOMDocument. Объект имеет множество методов, наиболее важные их них перечислены в таблице.
| Метод | Значение |
| Load (url) | Загружает xml-документ |
| LoadXML (xmlString) | Загружает xml-документ |
| Save (targerStr) | Сохраняет документ в файл |
| CreateElement (name) | Добавление нового элемента |
| CreateTextNode (text) | Запись текста в документы/элемент |
| CreateAttribute (name) | Установка атрибутов для элемента |
| SelectSingleNode (patternString) | Ссылка на объект типа IXMLDOMNodeList |
| CloneNode (deep) | Копирование текущего элемента |
Как я уже сказал, методов достаточно много, поэтому, если тебе потребуется узнать о предназначении того или иного метода/свойства, то не поленись заглянуть в библиотеку msdn. В ней найдешь ответы на все вопросы. Код импорта новостей из файла приведен чуть ниже. Перепиши весь код и возвращайся сюда за объяснением. Перед переписыванием не забудь подключить модуль MSXML и ActiveX.
Импорт новостей
var
_rss_doc: IXMLDOMDocument;
_node: IXMLDOMNode;
i:Integer;
begin
if not (openDialog1.Execute) then Exit;
//Инициализция
_rss_doc:=CoDomDocument.Create;
_rss_doc.async:=false;
//Загружаем документ
_rss_doc.load(OpenDialog1.FileName);
//Если возникла ошибка, то показываем сообщение
if _rss_doc.parseError.errorCode<>0 then
begin
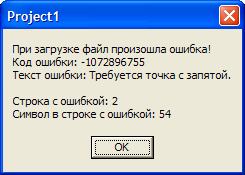
ShowMessage('При загрузке файла произошла ошибка!'+#13#10+
'Код ошибки: '+IntToStr(_rss_doc.parseError.errorCode)+#13#10+
'Текст ошибки: '+_rss_doc.parseError.reason+#13#10+
'Строка с ошибкой: '+IntToStr(_rss_doc.parseError.line)+#13#10+
'Символ в строке с ошибкой: '+IntToStr(_rss_doc.parseError.linepos));
CoUnInitialize;
Exit;
end;
//Получаем доступ к элементу rss
_node:= _rss_doc.selectSingleNode('//rss');
//В цикле получаем каждую новость
for i:=0 to _node.selectNodes('//item').length-1 do
begin
try
adotable1.Insert;
title.value:=_node.selectnodes('//item').item[i].selectSingleNode('title').Text;
link.value:=_node.selectnodes('//item').item[i].selectSingleNode('link').Text;
description.Value:=_node.selectnodes('//item').item[i].selectSingleNode('description').Text;
pubDate.Value:=_node.selectnodes('//item').item[i].selectSingleNode('pubDate').Text;
author.Value:=_node.selectnodes('//item').item[i].selectSingleNode('author').Text;
adotable1.Post; adotable1.Post;
except
End;
end;
Перед тем как начать парсить, нам нужно инициализировать объект типа IXMLDomDocument. В моем случае это переменная _rss_doc. Инициализация происходит стандартным способом – посредством вызова метода Create у сокласса CoDomDocument. После инициализации необходимо отключить асинхронный режим. Для нашего примера он не пригодится. Теперь надо попытаться выполнять саму загрузку. Загрузка выполняется с помощью метода load. В качестве параметра ему нужно передать имя файла, который и будет загружен. Загрузив файл, парсер начнет проверять его на корректность. В случае нахождения ошибок процесс парсинга прервется, и нам придется показать сообщение об ошибке, освободить выделенную память и остановить дальнейшее выполнение процедуры.
При возникновении ошибки есть возможность показать дополнительные сведения, которые помогут исправить документ, и попробовать загрузить его снова. В качестве таковых я показываю код ошибки (parseError.errorCode), текст ошибки (parseError.reason), номер строки с ошибкой (parseError.line) и символ в строке, с которого начинается ошибка (parseError.linepos). Располагая этой информацией, легко найти и исправить ошибку.
Вернемся к нашему коду и представим, что никаких ошибок не возникло, и следовательно, нам можно начинать выдергивать новости. В переменную _node мы получаем ссылку на элемент
_node:= _rss_doc.selectSingleNode('//rss');
В качестве единственного параметра ему нужно передать имя элемента. Получив родительский элемент, мы запросто сможем обратиться к любому дочернему (вспомни структуру RSS-файла, все имеющиеся элементы/тэги как раз и являются дочерними по отношению к
_node.selectNodes('//title').length
Так же я узнаю, сколько всего в документе элементов
adotable1.Insert;
При вызове этого метода в таблице создается новая пустая запись. Нам лишь остается заполнить все поля. В качестве значения для поля title (заголовок) я присваиваю содержимое элемента title текущего элемента item.
_node.selectnodes('//item').item[i].selectSingleNode('title').Text;
Остальные поля получают значения тем же способом. Когда все поля будут заполнены, желательно сохранить внесенные в таблицу изменения. Для этого я вызываю метод post компонента adoTable.
Экспорт новостей в RSS
Произвести импорт новостей нам любезно помог парсер от дяди Билла. Экспорт новостей из базы в файл можно осуществить таким же способом. Все, что тебе потребуется, - это немного времени на разбор методов: CreateElement(), CreateTextNode(), CreateAttribute(), CreateNode().
Работа с этими методами ничуть не сложна, кроме того, все нюансы расписаны в msdn. Поэтому экспорт новостей описанным способом я оставляю под твою ответственность. В крайнем случае ты всегда можешь задать мне вопрос по мылу. В своем примере экспорт новостей я организовал более простым способом. Наиболее важные моменты кода приведены ниже. Весь процесс организован на стандартных функциях добавления/сохранения текста в файл. Комментарии излишни. Единственное, на что стоит обратить внимание, - это перебор всех записей в таблице нашей БД. Количество записей хранится в свойстве RecordCount. Перед тем как перебирать записи, нужно установить курсор на самую первую. Это делается с помощью метода First компонента AdoTable. После чтения значений всех полей очередной записи, нужно передвинуть курсор, иначе мы постоянно будем получать одни и те же значения. Переход на следующую запись осуществляется методом Next все того же AdoTable.
Экспорт новостей в файл
var
_header:string;
_bottom:string;
_rss_file:TStringList;
_temp:Widestring;
i:integer;
begin
_header:='<?xml version="1.0" encoding="windows-1251"?>'+#13#10+
'<rss version="2.0">'+#13#10+
'<channel>'+#13#10+
'<title>Новости моего суперпортала</title>'+#13#10+
'<link>http://vr-online.ru</link>'+#13#10+
'<description>Суперпопулярный канал</description>'+#13#10+
'<lastBuildDate>Sun, 05 Aug 2007 07:30:01 +0400</lastBuildDate>'+#13#10+
'<ttl>1</ttl>';
adoTable1.First;
for i:=0 to adoTable1.RecordCount-1 do
begin
_temp:='<item>'+#13#10+
'<title>'+ClearText(title.AsString)+'</title>'+#13#10+
'<link>'+ClearText(link.AsString)+'</link>'+#13#10+
'<description>'+ClearText(description.AsString)+'</description>'+#13#10+
'<author>'+author.AsString+'</author>'+#13#10+
'<pubDate>'+pubDate.AsString+'</pubDate>'+#13#10+
'</item>';
_rss_file.Add(_temp);
adoTable1.Next;
end;
Coding complete
Итак, твой первый RSS-агрегатор готов, надо начинать тестить. В качестве теста попробуем скормить ему файл с лентой новостей сайта твоего любимого журнала (www.xakep.ru). Берем качалку (причем не любую, а свою - читай статью «Delphi для качков») и сохраняем данные с www.xakep.ru/articles/rss/default.asp?rss_cat=post. Получившийся файл пробуем открыть в нашей программе. В случае отсутствия ошибок твоя база данных заполнится последними новостями www.xakep.ru.
Статья опубликована журнале "Хакер" (http://xakep.ru). Октябрь 2007 г.
Ссылка на опубликованную статью сайта издания: http://goo.gl/FDkh2W
Ссылка на журнал: http://goo.gl/OiGHYi